We are pleased to announce the release of our new 3.0 ORCID API. We’re excited about the new features it contains, including several new affiliation types, a new research resources section, token delegation to enable permission sharing between members, and improved transparency about the source of information in ORCID records.
New affiliation types
With the help of the community, we have expanded our affiliation section so that researchers can be associated with — and get recognition for — a wider range of professional activities. The ORCID Registry now supports seven types of affiliations in four sections:
- Education and (new) qualifications: the formal education relationship between a person and an organization, either in a higher/tertiary education program, a professional or vocational training program, a certification, or a continuing education program
- Employment: a work relationship between a person and an organization
- Invited positions and distinctions (new): formal relationships outside of employment between a person and an organization, such as serving as a visiting researcher, an honorary fellow, or being distinguished with an award or honorary degree
- Membership and service (new): membership in an organization, or donation of time or other resources in the service of an organization
The API represents all of these affiliations in a similar way, so expanding an integration to use them is straightforward. They have been available in the user interface for several months now, and researchers have already been busy adding them to their records themselves, with 39,855 distinctions added as of this week, 34,685 invited positions, 94,302 memberships, 107,894 qualifications, and 30,832 service affiliations.
For more information, please see New Feature Alert: Upgraded Affiliation Types and our new workflow documentation for Invited positions and distinctions and Membership and service.
Research resources
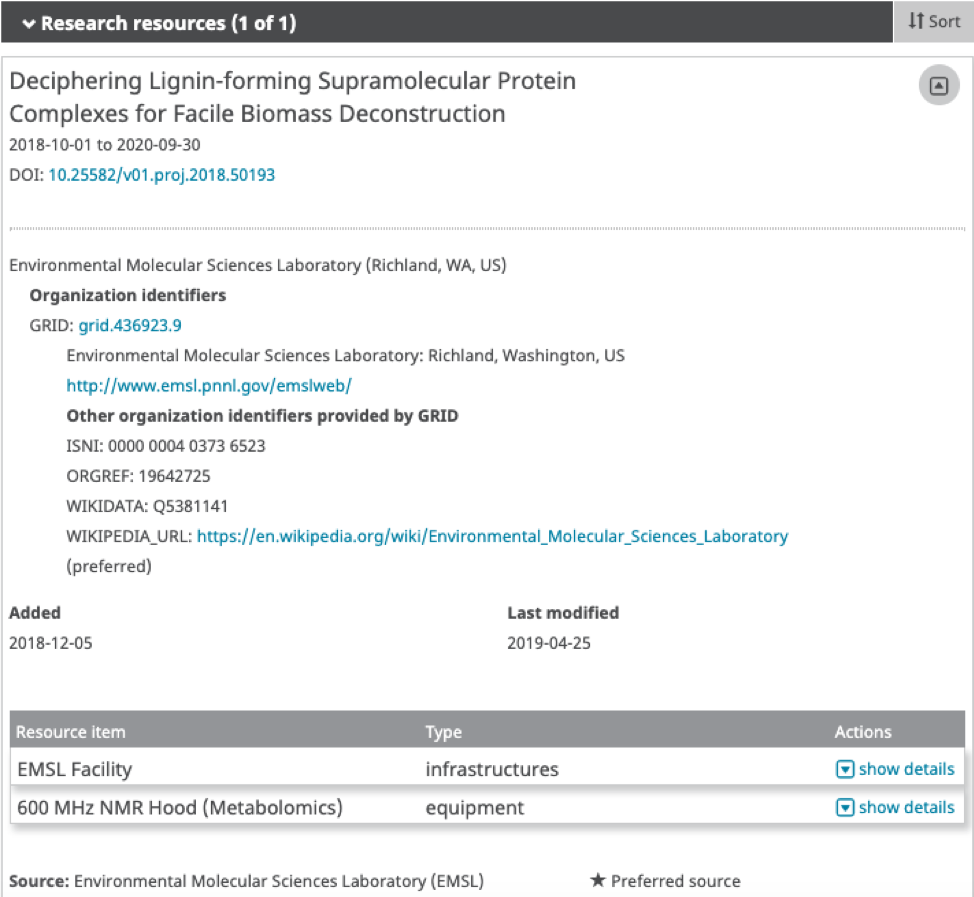 Our new research resources section connects people with the facilities and equipment they have been granted access to use. Last year our User Facilities and Publications Working Group helped define how these should appear within our API. Since then, several working group members have started adding research resources with our beta API, which was announced in Research Resources Now Live!
Our new research resources section connects people with the facilities and equipment they have been granted access to use. Last year our User Facilities and Publications Working Group helped define how these should appear within our API. Since then, several working group members have started adding research resources with our beta API, which was announced in Research Resources Now Live!
It’s great to see this evolve from an initial conversation with one member, to a community working group that developed a recommendations working paper, then on to a pilot implementation phase, and now into our production API. In addition, the working group helped establish requirements for tagging research resources in journal articles that are now incorporated into NISO’s recently released JATS 1.2 standard. More information is available in our research resource workflow documentation and there is a research resources API tutorial as well.
Blazing the trails of research resource acknowledgement are the Environmental Molecular Sciences Laboratory, Oak Ridge National Laboratory, and the Extreme Science and Engineering Discovery Environment (XSEDE), with several others in development. Publishers are also participating, with Wiley piloting the inclusion of research resources used in the production of submitted manuscripts in a unique acknowledgements section.
See the Source
Transparency is a core value of ORCID. We have been working to enable more transparency about the sources of information posted to the ORCID Registry, and API 3.0 now 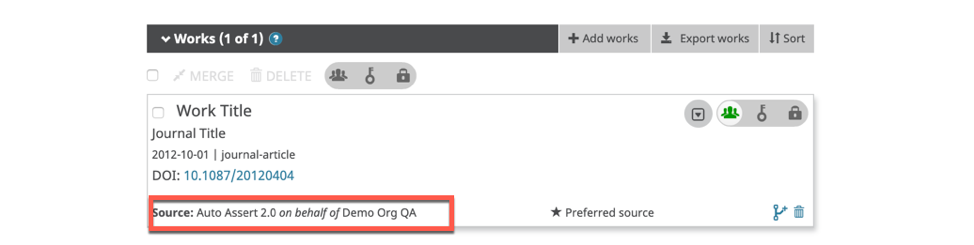 distinguishes between the source of the ORCID iD → item connection, and the source of the item → ORCID record connection. See Assertion Assurance Pathways: What Are They and Why Do They Matter for more information on why being able to see the source is so important to us.
distinguishes between the source of the ORCID iD → item connection, and the source of the item → ORCID record connection. See Assertion Assurance Pathways: What Are They and Why Do They Matter for more information on why being able to see the source is so important to us.
Ensuring researcher control is a key facet of “See the Source”, including assurance that researchers have given permission to use their iD and also including organization identifiers to clarify source identity.
Items in records now display information about the member that made the connection between the iD and the item (the assertion origin), as well as the member that used the API to add the item (the source). Learn more in Where can I see the source of information in my ORCID record?
“Seeing the Source” also makes it clear when one member has enabled another to act on their behalf by sharing permissions. We’ve updated our service provider workflow to reflect these changes, as well as creating a token delegation API tutorial, which provides more detail on these workflows.
Other changes
Normalizing identifiers. We’ve introduced a new system-generated field, which expresses external identifiers (DOIs, PMCID, PMID, ArXiv, Bibcode, ISSNs, and ISBNs) in a normalized format for the purposes of matching and grouping. Normalization is done based on the rules of the identifier type, and may include setting all alpha characters to lowercase, or transforming spaces, dashes, periods and other characters that can be treated as equivalent. It also adds standard prefixes and suffixes as appropriate. For example, https://doi.org/10.1/123, 10.1/123, and https://dx.doi.org/10.1/123 will all appear in this field as https://doi.org/10.1/123. The existing identifier value is unmodified.
New work types. In response to community feedback, we’ve added or modified several work types, including:
- Adding ‘preprint’ and ‘software’ to the list of supported work types
- Migrating ‘dissertation’ to the more general ‘dissertation-thesis’
- Improving the way we manage work types in API 3.0, enabling us to add new work types without requiring schema changes
Other work types under consideration for adding to the Registry in future include annotations and physical objects (specimens, samples, etc).
New ID relationship type. As announced in New Features Alert! Improvements to Adding and Grouping Works, we’ve also added a new identifier relationship type of ‘version-of,’ to clearly show where one work is a version of another. This can be used to relate multiple versions of a dataset together, or to group preprints with the published version of a paper.
Upgrading
We learned a lot during the transition from API 1.2 to API 2. This time we’ve made the upgrade much easier to manage. API 3.0 adds new functionality while only modifying existing functionality when absolutely necessary. This means integrators should be able to switch to the new API with a minimum of fuss. It also means that, although we recommend you start to plan your upgrade as soon as possible so that your organization and researchers can benefit from the new features, you have a lot of flexibility in deciding when to update to 3.0.
The small list of potentially breaking changes are in our API release notes here and here. There are a few changes around optional/mandatory fields, JSON enumerations have been modified slightly, and we also have a small refactoring of our XML schemas, adding some new fields to contain the metadata required for the new functionality.
Sunsetting older versions
API 3.0 will be the default API version from September 27, 2019, when we will also remove all API 2.0 release candidate versions. However, we will continue to support API 2.0 and 2.1 for the foreseeable future, and will provide at least 12 months notice before switching off those versions.
Documentation
- User documentation is available for the new affiliation types and the research resources section, as well as for seeing the source of information on ORCID records
- Full technical documentation, including new and updated workflows, is available on our API Resources pages
- Detailed API documentation, including schemas, is available on GitHub
A big thank you to our beta testers for their feedback, to ORCID staff — especially the Technical Team — for their hard work developing our API 3.0, and to everyone in our community for your suggestions and support. If you have any questions or concerns about this new version of our API, please share your comments by joining the ORCID API User Group.
